Building Reliable Edge AI Systems
Edge AI systems represent the frontier of modern machine learning. Deploying complex models to remote gateways requires shifting our mindset from "maximum accuracy" to "balanced latency, power, and size."
In this article, we outline the primary techniques utilized to optimize computer vision pipelines on standard CPU architectures.
The Bottleneck: Neural Compute on the Edge
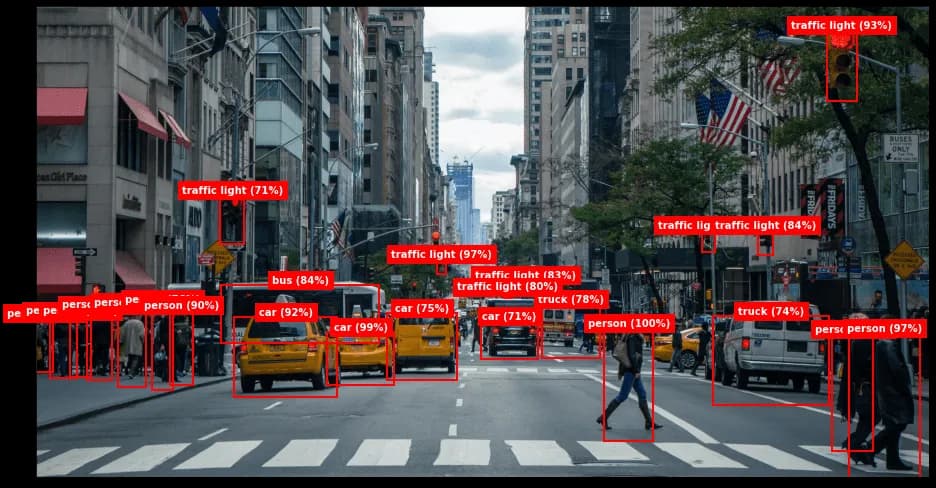
Traditional deep learning models require heavy GPU nodes to run inference in milliseconds. However, IoT setups, home cameras, and robotics systems operate on low-power CPUs with limited memory bandwidth.
A standard MobileNet-SSD running on an edge node faces three main constraints:
- Memory Latency: Transferring weights between RAM and the processor caches.
- Compute Cycles: The millions of floating-point operations (FLOPs) required per layer.
- Power Caps: Thermal throttling limits performance under prolonged workloads.
Core Optimization Techniques
To resolve these barriers, we leverage three optimization methods:
1. Model Quantization
Model quantization shrinks the precision of model weights from standard Float32 (32-bit floating point) to Int8 (8-bit integers). This reduces the memory size by 75% with negligible accuracy drop.
import tensorflow as tf
# Convert standard Keras model to quantized TFLite
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
with open('model_quant.tflite', 'wb') as f:
f.write(tflite_quant_model)
2. Depthwise Separable Convolutions
By replacing standard convolutions with depthwise separable filters, we split spatial filtering from channel merging. This lowers computational complexity by roughly 80%.
3. Layer Pruning
We drop weight connections that contribute minimally to classification decisions, creating a sparse neural network that compiles into smaller, faster kernels.
Practical Edge Pipeline Design
Deploying a model is only half the battle. A production pipeline must handle video frame ingestion, decoding, inference, and bounding-box updates smoothly.
Here is a typical layout diagram:
[!NOTE] Frame ingestion must be decoupled from the inference thread using double buffering. This ensures a slow inference step does not cause frame-drop warnings in the camera stream.
- Ingestion Thread: Reads camera feeds, decodes frames via OpenCV, and pushes them to a shared ring buffer.
- Inference Thread: Pulls frames from the buffer, performs downscaling, runs the neural net, and yields classification tensors.
- Rendering Thread: Overlays bounding boxes and logs events to local logs or databases.